
Two of my colleagues recently published blog articles that I would like to piggy back on. Don Miller recently discussed the importance of metadata when it comes to finding information in his blog post, The Magical Answer to Making Intranet Search as Awesome as Internet Search. Mark Aschemeyer then posted an article about the importance of connecting to all of the significant information inside a company in his post, Putting the Cart Before the Horse. Both posts are very valuable first steps in building a solid search foundation, and in this post, I will share ideas on things customers can build once they have appropriate metadata and connectivity established.
One of the consistent challenges I have seen across companies in many industries is difficulty in finding information that is related to a specific item or asset. For example, a user at a transportation company may be looking for maintenance documents related to certain vehicles, or an attorney in a law firm is trying to find information related to specific clients or matters. If I use the concepts above to connect to and tag all of the documents, then this can be relatively simple when looking for a particular asset (i.e. I want the maintenance records for one specific vehicle).
Where it gets more complicated is when I want to find content associated with multiple items. Let’s say I want to see the maintenance documents for all vans that are assigned to a certain location. The challenge is that the metadata I want to use – vehicle type and location – is assigned to the vehicles, not the documents. Therefore, to find the documents, I must first search for the vehicles using those tags to refine my results to the vehicles I want and then look at each of the vehicles individually to see associated documents – not a very productive approach.
Sticking to the example above, Related Search solves this problem by allowing the user to search for content – maintenance documents – using metadata associated with an item or asset – vehicles in this case. Under the covers, it automates the steps described above (i.e. captures a list of vehicles that match the criteria the user selects then returns the documents associated with those vehicles). So, in a single search, the user can see all the documents related to vehicles that match the criteria rather than looking one vehicle at a time.
As a perfect example of this, I was working with Apache Corporation when they brought a problem to my attention. The Land Lease Management Group was struggling to keep up with requests for information relating to an asset such as land or all the leases for a lessee. Sometimes it would take them weeks before they could gather all of the information, and as they started acquiring more assets, it was only getting worse.
Using the techniques described by Mark and Don, we proposed and built a search-based solution that would connect to their primary store of information, FileNet, as well as added metadata from a database system called Tobin to provide a single screen of information for the land group to work with. The time to search and find information went from days and weeks to mere seconds, and they could now handle many more requests.
In many industries, what happens is what I call the “swivel chair” problem where you have two screens on your desk and type two different IDs in each of the screens and swivel back and forth to see all of the information from multiple systems as you try to relate it together manually. As you can imagine, this gets very time consuming and in most instances it does not meet the business needs or timelines.
The described implementation was Apache’s first search-driven application, and once they built it, they recognized a pattern which they decided to repeat for other assets in their company. The next solution they built was a 365 degree view of an oil well. It allows a user to enter an oil well ID to pull up relevant information about it, such as location, lease, performance, experts and maintenance history in one screen. Apache plans to expand this pattern to even more entities, including suppliers and customers.
The process for building a solution like this does not need to be difficult. And, as I suggested above, it can apply to many similar uses cases in other verticals. We have done similar implementations in the legal market around clients and matters, in financial services around investments, and in construction and high technology around “accounts“ or “customers” for sales and cross-selling.
The approach we took is to start with a design of the information you want to see on a screen about a specific asset or entity. The screen shot below is an example of important information that might need to be displayed.
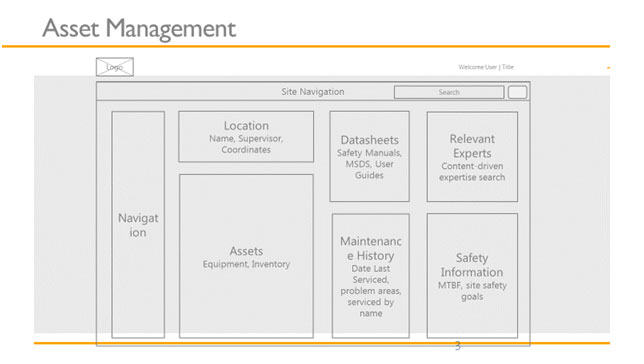
Once you understand the information that is required, you then need to determine where that information comes from. It typically involves connecting to multiple systems for information as well as applying metadata to link all of the information together. Once connectivity is established and metadata is applied, you then write the appropriate queries based on the information needed from your design above and end up with a solution like the screenshot below. In this case, the asset is an oil well, but it could easily be an airplane, a client/customer, or a retail location.
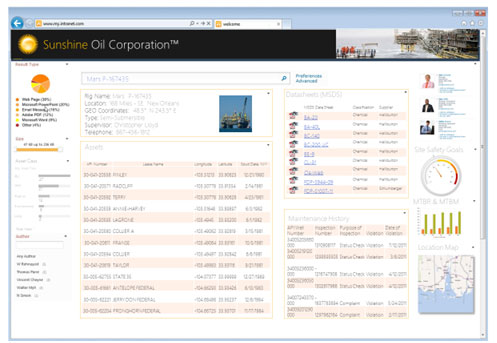
This pattern of pulling together information and metadata from disparate systems is a strength of search, and as you add more connectivity and metadata over time, the number of applications you can build will increase. Following a pattern like this will not only decrease the time it takes to deploy solutions, but it will also eliminate the “swivel chair” problem and let employees make faster and better informed decisions.